Artykuł / wywiad
Korpus Dyskursu Literaturoznawczego
Korpus Dyskursu Literaturoznawczego (KDL) to jeden z kluczowych zasobów tekstowych opracowywanych przez Instytut Badań Literackich Polskiej Akademii Nauk w ramach projektu DARIAH-PL. Obejmuje on polski dyskurs literaturoznawczy XIX–XXI wieku (lata 1822–2022). Znajdą się w nim teksty poświęcone literaturze lub ukazujące się w czasopismach czy antologiach o profilu literaturoznawczym. Szeroki zakres czasowy (200 lat) pozwoli zarówno zgromadzić reprezentatywny materiał, jak i uchwycić procesy kształtowania się dyskursu literaturoznawczego w Polsce.
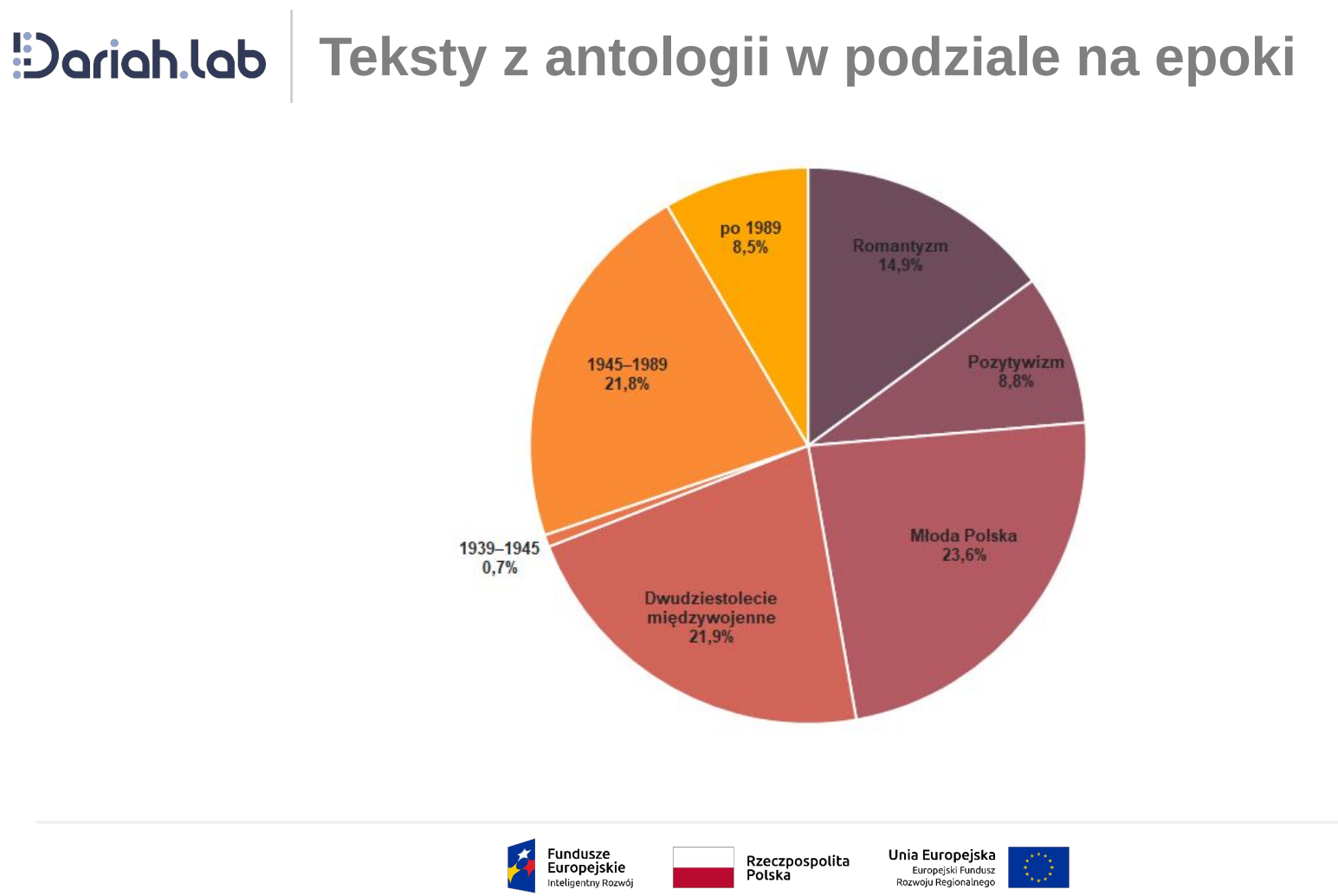
Korpus zostanie wykorzystany przede wszystkim do utworzenia nowego słownika terminów literackich i trenowania statystycznych modeli językowych. Efektem tych prac będą narzędzia służące do automatycznej ekstrakcji terminologii i bytów (m.in. postaci literackich, nazwisk autorów/ek, badaczy/ek i tłumaczy/ek literatury, tytułów utworów oraz nazw grup literackich i instytucji kultury), określania relacji między rozpoznanymi bytami oraz wskazywania tematyki tekstu. Dodatkowo użytkownicy/czki będą mogli przeszukiwać korpus m.in. za pomocą słów kluczowych, uzyskując dostęp do niewielkich fragmentów tekstów o objętości nieprzekraczającej akapitu. Powstanie również otwarta wersja KDL, zawierająca teksty (głównie starsze), które można udostępnić w całości.
Prace nad pierwszą wersją korpusu zostaną zakończone jesienią 2023 roku. W kolejnych latach KDL będzie rozszerzany o prace najnowsze, a równocześnie pogłębiany poprzez uzupełnienia w postaci wcześniej niedostępnych tekstów.
Osoby zainteresowane korpusem proszone są o kontakt z pracownikami Centrum Humanistyki Cyfrowej IBL PAN:
-
Agnieszka Karlińska, agnieszka.karlinska@ibl.waw.pl
-
Maciej Maryl, maciej.maryl@ibl.waw.pl.
Prezentacja na temat Korpusu Dyskursu Literaturoznawczego (w formacie .pdf) >>
Informacje
Zobacz także
7 pytań, które warto sobie zadać tworząc korpus do badań
Korpusy, czyli zbiory danych tekstowych, dobranych zgodnie z określonymi kryteriami i odpowiednio opisane, stają się coraz bardziej popularnym narzędziem pracy naukowców i naukowczyń reprezentujących różne dyscypliny. Korzystają z nich przedstawiciele i przedstawicielki dyscyplin takich jak językoznawstwo, ale i socjologia, historia, psychologia, a od pewnego czasu także literaturoznawstwo. Dzięki wykorzystaniu korpusów możliwe jest przetwarzanie zbiorów danych wielokrotnie przekraczających możliwości analityczne człowieka-badacza, co pozwala na stawianie zupełnie nowych pytań badawczych oraz poszukiwanie nowych odpowiedzi na pytania już znane.
Tekst, korpus, wykres. Cyfrowa analiza literatury – przydatne narzędzia
Czy (a może jak?) komputer może czytać literaturę? Choć poziom „rozumienia” tekstu literackiego przez komputer nie odpowiada temu, jak rozumie go człowiek, to narzędzia cyfrowe mogą wydatnie wspomóc różnego rodzaju badania literackie. Dziś nie musimy już ręcznie liczyć wystąpień interesującego nas słowa w tekście. Dzięki zaawansowanym wyszukiwarkom możemy wyszukiwać całe frazy i podobnie zbudowane fragmenty, a lista słów użytych w badanym przez nas utworze może powstać w kilka chwil.
Rozmowy „Biuletynu Polonistycznego” - KorBa
Przygotowany i zrealizowany przez Pracownię Historii Języka Polskiego XVII i XVIII w. Instytutu Języka Polskiego PAN we współpracy z Zespołem Inżynierii Lingwistycznej w Instytucie Podstaw Informatyki PAN projekt „Elektroniczny korpus tekstów polskich z XVII i XVIII w. (do 1772 r.)” miał swoją uroczystą premierę 18 czerwca 2018 r. Najważniejszym rezultatem projektu jest udostępniony w Internecie Elektroniczny Korpus Tekstów Polskich XVII i XVIII w. (do 1772 r.), w skrócie nazywany Korpusem Barokowym. Od tej ostatniej nazwy urobiony został akronim KorBa. Projekt był finansowany ze środków Narodowego Programu Rozwoju Humanistyki na lata 2013-2018. Z panem profesorem Włodzimierzem Gruszczyńskim, kierownikiem projektu, oraz panią doktor Renatą Bronikowską, koordynatorką projektu, rozmawiamy o „wczytywaczu”, „tagerach”, i „transkryberach” – a także innych narzędziach humanistyki cyfrowej.
Apel do lingwistów korzystających z zasobów i narzędzi językowych
Szanowni Państwo! My niżej podpisani współtwórcy zasobów językowych (korpusów tekstów, słowników elektronicznych itp.) oraz narzędzi językowych (wyszukiwarek korpusowych, analizatorów morfologicznych i składniowych itp.) zwracamy się do Państwa z prośbą o cytowanie publikacji prezentujących te zasoby i narzędzia w Państwa pracach, które je wykorzystują. (Publikacje takie zwykle są wymienione na stronach WWW poświęconych takim zasobom i narzędziom).